BLOG
The Infrastructure Call Most AI Teams Are Making Too Late
June 30, 2026 · Daniel Miodovnik, COO

Key Takeaways
First, the Colossus lesson: What does it actually tell us?
In September of 2024, xAI announced it had built Colossus, a 100,000 GPU cluster in Memphis, in 122 days. The headline circled the industry within hours, with investors citing it, competitors benchmarking against it, and operators asking their construction teams why their own projects were taking three times as long.
What the headline didn't carry was context; Colossus occupied a shuttered Electrolux factory with existing utility feeds and a concrete shell already in place. So instead of telling us how fast a data center can be built from scratch, the Colossus example actually tells us how fast you can deploy into an existing shell with power already connected. Those are very different problems.
The broader dataset shows what construction from a typical starting point actually looks like. Epoch AI buildout speed dataset puts the realistic industry range for genuine new construction at 1 to 3.6 years for 1 GW facilities. Stargate Abilene's 0.3 GW first phase came online in late 2025, but the full 1.2 GW isn't estimated to be operational until Q1 2027. Second-wave Stargate sites like those in Shackelford County Texas and Michigan are targeting Q4 2028, roughly a 36-month program from site selection to commissioning.
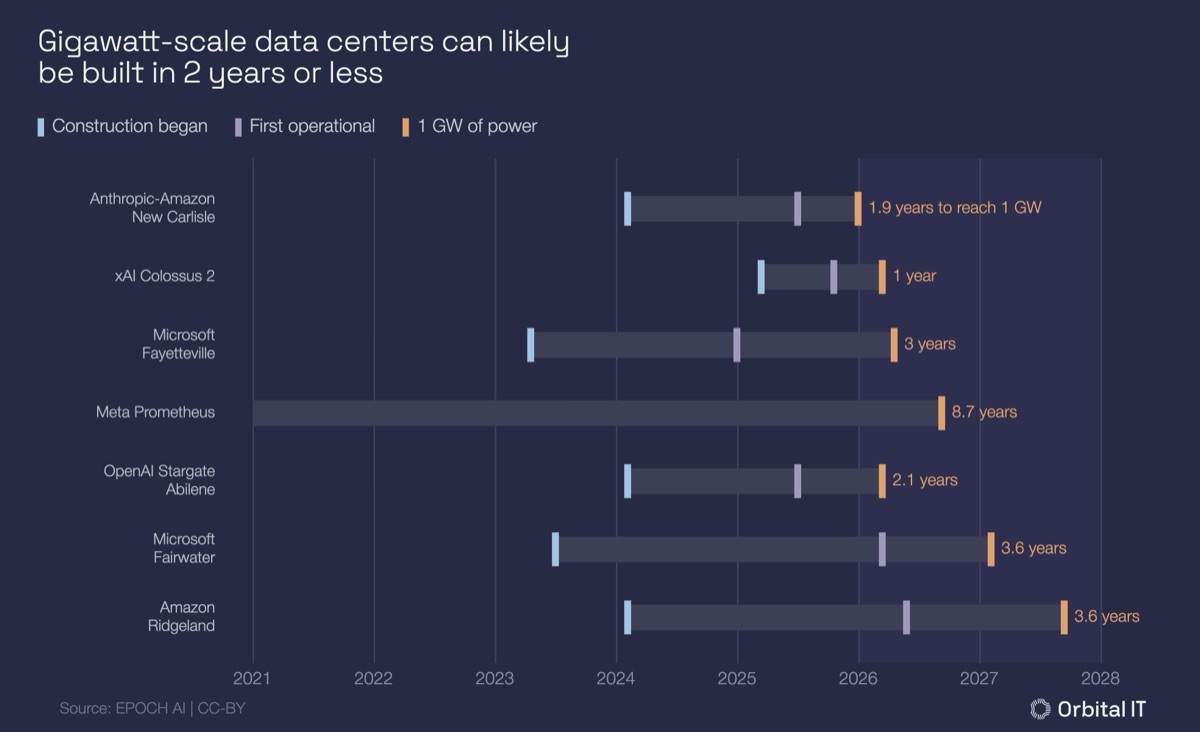
Data from Epoch AI data center buildout speeds (as of November 2025).
The takeaway isn't that 122 days is impossible; it's that the timeline depends on where you start. Greenfield, brownfield, and powered shell deployments each carry a different clock, and the programs that hit aggressive timelines repeatably aren't finding lucky factories. They're resolving constraints before the compute order is placed, whatever the starting conditions.
Is there still room to compete?
What made Colossus fast was that the constraints were already resolved; the building existed, the power was connected. That principle is repeatable from any starting point. Programs that consistently hit aggressive timelines do it through purpose-built modular components, factory-tested and signed off before they ship, arriving on site ready to connect rather than ready to start building. Modular prefabrication is how that scales across greenfield, brownfield, and powered shell deployments alike: not adapting what exists, but manufacturing what's needed so that site work compresses to assembly rather than construction.
The Modular Argument
What's shifted modular from a procurement preference to a default assumption is straightforward arithmetic. Per CMIC Global's 2026 construction trends report, traditional data center builds run from around 18 to 24 months from groundbreak, while modular strategies have compressed that materially. At $8.5M per MW per year in total cost of ownership for AI training clusters, a single month of delay on a 10 MW deployment costs roughly $7M in carried infrastructure cost, covering financing, opex, and depreciation on assets.
But that figure only captures what's being spent during a delay, not what you're failing to earn. On the revenue side, the picture is considerably larger. A GB200 NVL72 rack running DeepSeek R1 produces approximately 964,000 output tokens per second, based on 13,386 output tokens per second per GPU across 72 GPUs. At DeepSeek R1's published output price of $2.50 per million tokens, that translates to roughly $8,600 in token revenue per rack per hour, or around $6M per rack per month at full utilization. With that in mind, infrastructure decisions causing delays deserve serious financial scrutiny, not just operational attention.
Prefabrication compresses the overall program significantly compared to conventional builds, eliminating the sequential dependency between factory build and site work, which is why the infrastructure decision matters long before the equipment order is placed.
Component lead times add a further layer to this. Switchgear lead times run twelve to eighteen months in many markets, with major transformers and generator step-up units often longer. No procurement relationship changes a manufacturing queue.
What modular construction changes is not the lead time itself but the room to maneuver around it. Because a modular program is designed and built in a factory environment, it can be revised when a constraint surfaces. The sequence of what gets manufactured when can shift, meaning other modules can advance, and the build can continue moving. A stick-built program on the other hand has to stop and wait, because reworking a live construction site is a fundamentally different problem from reworking a factory schedule. Identifying the long-lead components early and designing the build sequence around their delivery windows is as important as any other decision in the program.
Not all Modular Is Equal
But "modular" is a category, not a specification. Modular segments into three distinct delivery types: skidded, containerized, and hardened, each purpose-built for a different site profile. Each carries different thermal limits and serves a completely different role in a build program.
Skidded
Skidded modules are pre-assembled data center configurations mounted on structural steel frames, sized to fit any building envelope without highway transport constraints. They crane or roll into a powered shell under development or an existing building that already provides environmental control (temperature, humidity, and particulate management), connecting directly to the host structure's power and cooling infrastructure on arrival.
Skidded modules are the right choice for operators who have a building envelope, whether that's a new shell in development or an existing brownfield structure with controlled internal conditions.
Containerized
Containerized modules are self-contained units that manage their own temperature, humidity, and particulate control independently of the host environment. This makes them a building-in-a-building deployment: the module handles its own internal conditions while the host structure provides physical protection from the elements.
Containerized modules are designed to operate within a host building, such as a warehouse, industrial shell, or facility envelope that handles weather exposure. This is precisely what makes them well-suited to brownfield retrofits: the existing structure handles the external environment, while the module delivers a controlled, high-density compute environment inside it.
Hardened
Hardened is the outdoor-rated variant of the containerized form factor. The same self-contained module architecture, engineered for direct environmental exposure: reinforced enclosures, integrated environmental management, fire detection and suppression, deployed on a prepared pad where no host building exists.
An entire campus arrives as a coordinated set of factory-built modules: IT halls, electrical infrastructure, cooling, ancillary buildings. Site preparation and pad work run in parallel with factory build, compressing the overall program the same way a powered shell deployment does.
Where the site is bare land with no host structure, hardened is the form factor that needs to be applied.
What Vera Rubin Changes About Your Infrastructure

Most facilities planning for 2026 or 2027 deployments assume the cooling infrastructure from the last GPU generation carries over. For Vera Rubin, it mostly doesn't.
The deeper problem isn't the spec change itself, it's what previous infrastructure decisions lock you into. Facilities that integrated MEP (Mechanical, Electrical, Plumbing) directly into the building structure for GB200 now face a harder upgrade path: ripping out sunk-cost infrastructure or accepting reduced flexibility when the next generation arrives. Modular keeps MEP separate from the building, which means it can be upgraded without touching the host structure. That separation is the design decision that determines whether a Vera Rubin upgrade is a module change or a construction project.
"The mistakes I see most often aren't in the big decisions, but in the assumptions nobody writes down. A facility gets built, it works, and then the next hardware generation arrives and suddenly you're not just upgrading compute, you're rearchitecting cooling in a live environment. Data center architecture can't be static anymore, and modular construction changes the equation. The architecture evolves with the compute. When the next GPU generation lands, you're swapping a module, not rearchitecting a building."
— Eden Smalley, Senior Mechanical Engineer (MDC)
The Vera Rubin (NVL144) standard rack runs at approximately 190 kW per rack per NVIDIA's disclosed guidance, a significant step up from the Blackwell (GB300) generation at around 138 kW. The high-performance CPX variant runs considerably higher. These are sustained operating loads, not burst figures, so facilities must support them every hour the cluster runs.
At these densities, form factor selection and cooling architecture both matter. Skidded modules in a powered shell and hardened modules on an outdoor pad are both designed to accommodate the liquid cooling infrastructure these platforms require. Containerized deployments within a host building are similarly capable when the cooling system is correctly specified from the start. The critical variable is whether the design was built for current-generation loads or inherited from a previous one.
With approximately 75% of 2026 AI infrastructure CapEx (Capital Expenditure) heading toward compute and its supporting infrastructure, getting this choice right has rarely carried more financial consequence.
From 190 kW to 600 kW: The Window to Get This Right
The standard 190 kW NVL144 is one planning horizon. The CPX variant at 370 kW per rack is a different infrastructure conversation. And by 2027, Rubin Ultra (NVL576) arrives at around 600 kW per rack, confirmed by Jensen Huang at GTC March 2025. That's a 400% increase in rack density from the Blackwell (GB200) generation to Rubin Ultra across roughly three years.
Rack Density Progression 2010–2027 (kW per Rack)
| Year | Platform | kW/Rack |
|---|---|---|
| 2010 | Standard | 5 kW |
| 2020 | Standard | 12 kW |
| 2024 | Blackwell (GB200 NVL72) | 120 kW |
| 2025 | Blackwell (GB300 NVL72) | ~138 kW |
| 2026 | Vera Rubin (NVL144) | 190 kW |
| 2026 | Vera Rubin (NVL144 CPX) | 370 kW |
| 2027 | Rubin Ultra (NVL576) | TBC |
Sources: SemiAnalysis (2025), NVIDIA GTC (2025), The Register (2025)
Vera Rubin (NVL144 CPX) at 370 kW per rack is a different infrastructure decision again. Above 250 kW per rack, cooling architecture requires careful specification. The standard Vera Rubin (NVL144) at 190 kW uses single-phase liquid cooling. The CPX variant at 370 kW pushes into territory where cooling system design becomes a site-specific engineering decision; exact requirements for CPX deployments should be confirmed with your hardware partner before specifying infrastructure. And by 2027, Rubin Ultra (NVL576) arrives at 600 kW per rack. From Blackwell (GB200 NVL72) to Rubin Ultra (NVL576) in roughly three years, rack density increases fivefold.
Goldman Sachs projects US data center power demand will more than double to 66 GW by 2027, with only 50 to 60% of scheduled capacity expected to come online on time. The operators who close that gap fastest will be those whose infrastructure didn't top out two GPU generations ago.
The Infrastructure Decision
At current demand rates, lead times, and density trajectories, the question becomes which modular approach fits the workload. Containerized modules solve real problems at remote sites and brownfield buildings without controlled environments. Skidded modules compress timelines for operators who have a building envelope, whether new or existing. Neither replaces hardened modules when the requirement is a Vera Rubin-class AI cluster on bare land with a compressed delivery schedule.
The density trajectory makes this urgent. From 5 kW per rack in 2010 to 600 kW per rack in 2027, the industry has seen a 120x increase in thermal demand per rack in 17 years. The last three years of that curve are steeper than the preceding thirteen. Facilities designed for yesterday's density are not retrofit candidates; they are capacity that does not exist for the workloads that matter.
The procurement decisions made now, on form factor, on liquid cooling infrastructure, on delivery programs, are the ones that determine whether a facility comes online on schedule or falls behind. The infrastructure that closes it fastest is purpose-built for the job: designed from first principles for the site and workload, factory-tested and signed off before it ships, and sized for the density curves already on the roadmap, not the ones that were relevant two years ago.
Frequently Asked Questions
What is the real build timeline for a large AI data center?
The realistic industry range for 1 GW facilities is 1 to 3.6 years. Modular prefabrication compresses this to a matter of months for most programs, with appropriately scoped hardened or skidded module deployments achieving 180-day delivery targets. The xAI Colossus 122-day figure applied to a retrofit of an existing industrial shell, not a greenfield build.
What is the difference between skidded, containerized, and hardened modules?
Skidded modules mount on structural steel frames and deploy into a powered shell or existing building that provides environmental control. Without highway transport constraints, they integrate full liquid cooling infrastructure for high-density AI workloads. Containerized modules are self-contained units managing their own environment, suited to brownfield buildings where the host structure provides weather protection but not internal environmental control. Hardened modules are the outdoor-rated variant of the containerized form factor, for pad-built deployments with no host structure. Skidded and hardened modules are both designed to support Vera Rubin-class densities when correctly specified.
Can existing infrastructure support Vera Rubin (NVL144)?
Potentially, with upgrades. Vera Rubin requires roughly double the liquid cooling flow of the previous generation, not more pump pressure. CDUs (Coolant Distribution Unit) specified with adequate flow capacity can be upgraded, but facilities built around air-cooled containerized modules or undersized cooling infrastructure will need more than a CDU swap.
How much does a schedule delay actually cost for an AI data center?
At $8.5M per MW per year in total cost of ownership for AI training clusters, a one-month slip on a 10 MW facility costs approximately $7M in carried cost. That's more than the cooling hardware for roughly 200 Blackwell (GB300 NVL72) racks, based on approximately $49,860 per rack in liquid cooling hardware costs, per Yahoo Finance's 2025 component pricing analysis (cold plates, CDU connections, and manifold per rack). Schedule risk is a financial exposure, not just an operational inconvenience.
What is the Rubin Ultra (NVL576) and why does it matter for infrastructure planning now?
Rubin Ultra (NVL576) is NVIDIA's 2027 platform specified for around 600 kW per rack by Jensen Huang at GTC March 2025. Infrastructure decisions made today, particularly form factor selection and liquid cooling sizing, determine compatibility with that platform. Hardened and skidded module programs designed for Vera Rubin (NVL144 CPX) at 370 kW per rack are the closest available proxy for Rubin Ultra readiness.
